
What is so-vits?
So-vits, also known as SoftVITS singing voice conversion is a Python library that has been popularized by VeeTubers for resynthesizing voice input from one voice into another. It originally was designed to let developers give singing voices to anime characters. Over the past year, a number of services have misused this technology by integrating it into products used to create fake versions of real people’s voices and these services resulted in people producing fake versions of popular artist’s songs. Additionally, some artists have embraced the technology, encouraging aspring producers to license their vocal likeness for use in their creations.
What does so-vits do and how is it useful for producers?
So-vits transforms a source voice into a target voice by altering pitch and then using adversarial networks to iteratively match the source voice to a target voice while varying the source. In the studio, a producer can recreate a singer’s voice from an input corpus of data (e.g. the vocals they’ve recorded) and can then sing using their own voice and apply the singer’s voice to thier own. This is useful because sometimes you want to alter, fix, or otherwise correct a performance without needing to bring the artist back into the studio for things like producing a non-explicit version of a vocal.
Setting up so-vits
I found it easiest to use a fork of so-vits that incorporates several convenient libraries and enhancements.
You need to have a system with Python installed on it and some familiarity with installing Python packages. From the command prompt, you then setup so-vits:
pip install -U so-vits-svc-forkIt can be helpful to install all of the ML depenencies as you would typically do for working in Python, meaning install the SDK for your version of the NVidia Cuda Compiler, TensorFlow, and other Python dependencies.
pip install praat-parselmouth
pip install ipywidgets
pip install huggingface_hub
pip install pip==23.0.1 # fix pip version for fairseq install
pip install fairseq==0.12.2
pip install numpy==1.21
pip install --upgrade protobuf=3.9.2
pip uninstall -y tensorflow
pip install tensorflow==2.11.0It’s also helpful on some systems to use Conda for isolation of Python dependencies. Setting up a computer for ML is probably a topic best covered elsewhere.
How do I use so-vits for synthesizing vocals given a model?
The easiest way to do this is to instantiate the sovits voice conversion GUI:
svc gui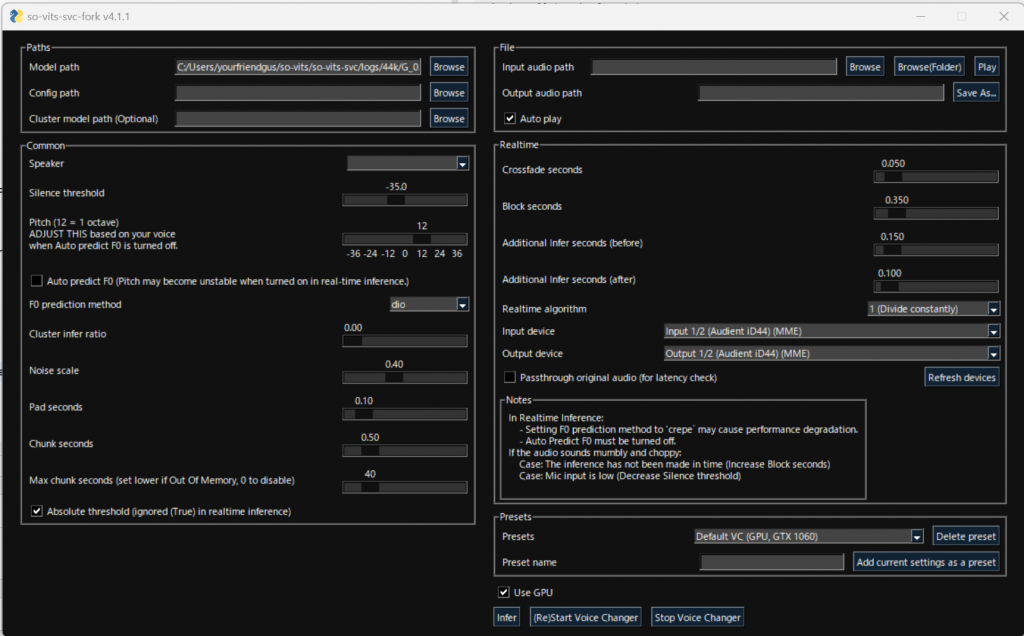
After the GUI loads, you can select your model checkpoint, the input audio (the singing you want resynthesized into the model voice), and the output audio which will be the input in the new voice.
How do I train a new so-vits model?
The following commands will generate a so-vits model given a vocal track.
pip install -U so-vits-svc-fork
mkdir trainPlace the vocal from your singer in the train folder, e.g. train\dataset_raw_raw\walking-in-the-rain-looking-for-rainbows-vox\vocal_clean.wav and then run the following commands which will pre-process the input audio for training. It can be helpful to further isolate your vocal input from background noise or instrumentation using tools like UVR or its spiritual ancestor, Spleeter.
svc pre-split
svc pre-resample
svc pre-config
svc pre-hubert
svc train -tNote that I had to make some minor changes to the utils.py script that were causing errors on my machine, e.g. replace the line that said checkpoint = ...(true) to checkpoint = ...(false) as indicated in the debug logs from the tensorboard during the script run.
When you’ve successfully started training, a tensorboard will load and you can monitor the training progress. I like to set up a Weights and Biases configuration to log the output to my wandb dashboard while training is happening.
After you have trained the model for around 10,000 iterations or so, you can use the checkpoint it outputs as your model for synthesis.
Cleaning things up and creative processing
The output from so-vits is usually not refined enough to release so you will want to perform vocal processing using a processing chain similar to producing the original voice and can clean things up with tools like Auto-tune, Melodyne, and so on. I hope you find this to be a valuable tool for making music!